






英伟达的总裁黄仁勋(Jensen Huang)在2025年11月伦敦AI峰会(London AI Summit):
“中国很可能在全球AI竞赛中获胜,因为它拥有海量的研究人才,以及政府提供的能源补贴,这些能支持大规模AI基础设施建设。”
其实,黄仁勋所谓的「中国会赢」的说法基本上正在或者已经得到了应验。
首先,聊天机器人的竞技场(Chatbot Arena)的曲线几乎完全重合。
在2025年 Q3-Q4,中国的开源大模型占前大模型系统榜单前10的~50%(DeepSeek、Qwen、GLM、Kimi),虽然,美国仍主导前2(算力/闭源优势),但是与美国的差距真的从“几年”缩到了“几个月”,而且还在继续压缩。
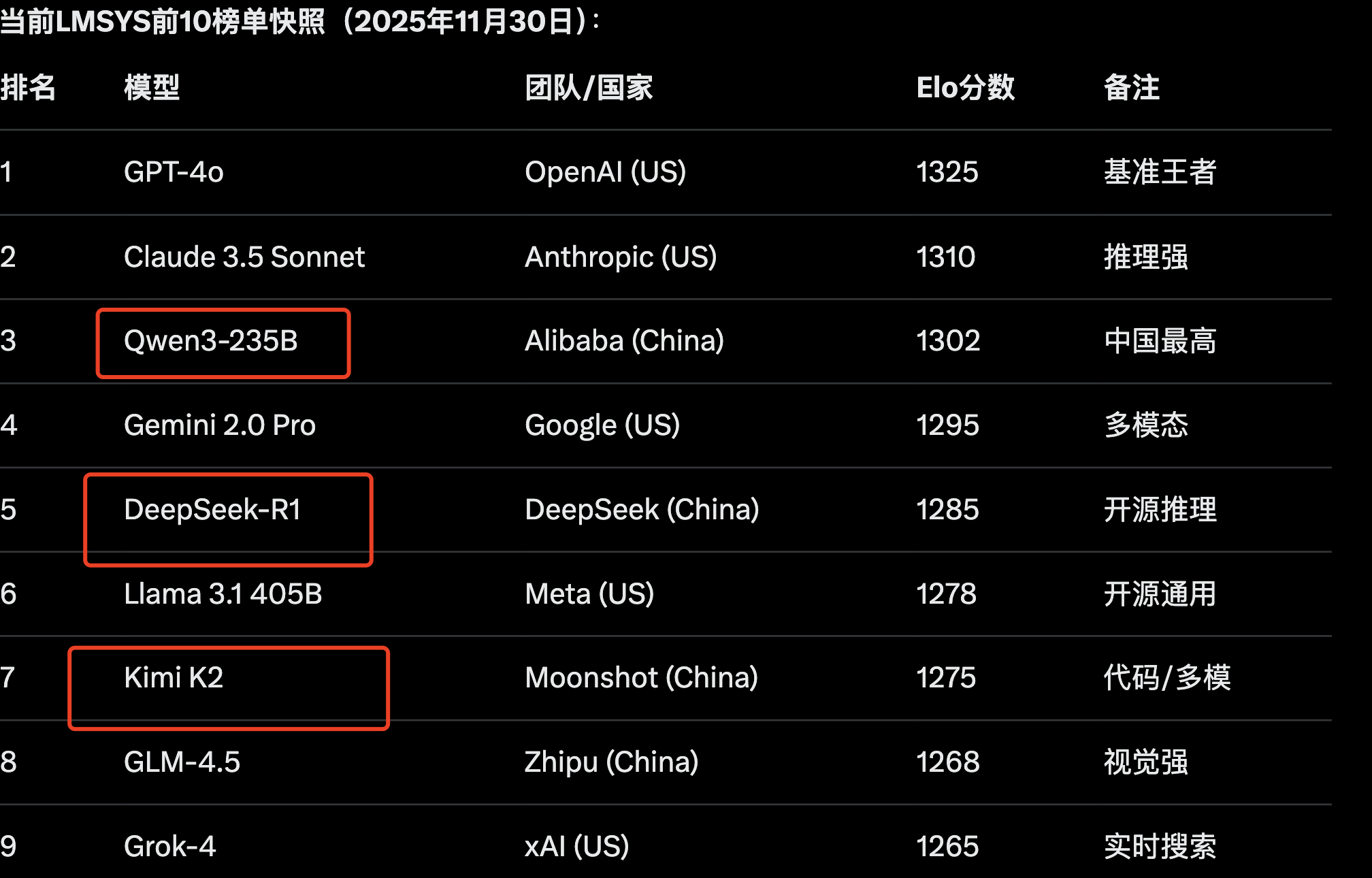
其实,不怕被嘲笑,中国科技崛起从来只用一个剧本:
那就是两「chao」
首先是“抄作业”,再用抄来的作业把原作者卷到怀疑人生。
第一阶段:抄作业(2023-2024)
那一阵子,文心一言、通义千问、Kimi、豆瓣的界面、功能、甚至宣传语都被西方媒体截图并排,标题千篇一律,模仿ChatGPT。
没人否认,确实在抄。
但抄作业在提倡开源的时代,从来不是耻辱,而是起跑枪响。抄的核心,是把发表到arXiv(AI新技术的公告栏)的论文,当天就拆开复现。要知道在中国的开源社区如魔搭社区,几万人都是在线时刻等“投喂”。
美国那边的论文一发,中国团队立刻:①通读论文 ②下载代码(如果开源)③没有代码就自己手敲 ④改成能跑的版本。
他们用同样的方法、在自己的机器上重新训练或推理出论文里声称的性能(SOTA分数)。复现成功实际上等于彻底吃透了这项技术。
往往当天或24-48小时内,GitHub上就出现一个“xx-arxiv-reproduce”“xx-pytorch-version”之类的仓库,星标几小时破千,Hugging Face上就有人放出可直接下载的权重。
中国国内所有头部大模型实验室(阿里、智谱、字节、百度、DeepSeek、月之暗面、生数等)也都把官方权重首发在Hugging Face,然后再同步到魔搭。
为何中国团队能做到当天复现?因为中国很多公司很多公司把“论文当天复现”写进团队OKR,复现成功有奖金,妥妥地KPI驱动。加上完整工具链,vLLM、Transformers、DeepSpeed、昇腾、CUDA全都有成熟中文教程,一键脚本满天飞。在中国,工程师把「首发复现」当成了荣誉,让他们通宵干也愿意。
第二阶段:超车(2025-)
抄完了,就开始卷了。
这时候比的不再是智商,而是国运。
成本屠夫模式:
同一张H100,在美国3万刀,中国黑市曾炒到6万刀。但中国直接把昇腾910B、壁仞BR100、华为云燧人集群拉满,综合训练+推理成本已经降到美国的30-45%。
DeepSeek-R1官方披露训练硬件总投入约1.6亿美元,而业界估算Grok-4、Claude 4累计训练成本均超过50亿美元。
工程师红利彻底兑现:
2025年,中国大陆AI及相关专业应届毕业生约21-23万人(官方统计口径),美国约6.2万人(NSF数据)。
更重要的是,中国很多人仍愿意996,凌晨四点的中关村,从来不缺灯。
真实世界的降维打击
美国最强的模型还在帮人写诗,做rap、做PPT、画中世纪骑士抱着加特林,
中国最强的模型已经开始:
• 给派出所自动生成笔录(全国超3000个试点)
• 给工厂做钢厂级排产调度(宝钢、宁德时代已全量上线)
• 给三甲医院写超声报告(准确率已达95%+)
给外卖、物流、电商算最优路径(日均节省物流成本数十亿人民币) 这些场景听起来“low”,但每跑一单就多几GB真实标注数据,
每多几GB数据就能再训一代更强的模型。
2025年,中国大模型日均API调用量已达美国6倍以上(Scale AI & Epoch AI联合报告)。
国家意志的最后一击
当美国还在国会吵“AI要不要暂停六个月”,中国已经把“人工智能”连续第三年写进政府工作报告的“头号工程”。
电不够?“东数西算”八大枢纽全速扩容,内蒙古、贵州电价低至0.25元/度。
钱不够?1380亿美元国家引导基金+地方子基金已撬动超3万亿社会资本。
芯片不够?就举全国之力堆料、堆算法、堆生态。
黄仁勋看懂了剧本的最后一页。
AI的终局从来不是谁的模型参数更多、分数更高,而是谁能最快、最狠、最大规模地把AI塞进每一条生产线、每一座工厂、每一条马路。
所以,他会说:「In the end, China will be ahead」(最后,中国会领先的)这不是客套,也不是预言,而是已经看得见的趋势。
看看电商的发展和应用,你就会明白了。
中国科技崛起,从来就是这条路:先被全世界嘲笑抄作业,再用抄来的作业,把所有原作者卷到不得不承认
——作业本,现在归中国了。
这一次,也不会例外。